安装nbextensions
pip install jupyter_contrib_nbextensions
jupyter contrib nbextension install --user
安装 nbextensions_configurator
pip install jupyter_nbextensions_configurator
jupyter nbextensions_configurator enable --user
启动jupyter notebook
安装nbextensions
安装 nbextensions_configurator
启动jupyter notebook
记录excel(有密码)打不开,用python 还原。
使用 pip 安装软件时,使用国内镜像可以大大提高下载速度
常用国内镜像
https://pypi.tuna.tsinghua.edu.cn/simple/ # 清华大学
https://mirrors.aliyun.com/pypi/simple/ # 阿里云
https://pypi.douban.com/simple/ # 豆瓣
https://pypi.mirrors.ustc.edu.cn/simple/ # 中国科学技术大学
https://pypi.hustunique.com/ # 华中科技大学
永久使用
在用户的根目录下创建 .pip 文件夹,新建 pip.conf 文件
示例:
在文件中写入要使用的镜像
示例:
使用清华镜像
新方法
nbextensions 是 Jupyter 非常好的插件,它是将一系列 js 脚本嵌入到 Jupyter 中,增强 Jupyter 的交互式体验,可以让你的 Jupyter 变得非常强大。
执行上述命令后,重启你的 Jupyter Notebook ,打开 就可以看到 nbextensions 插件的配置页面了。
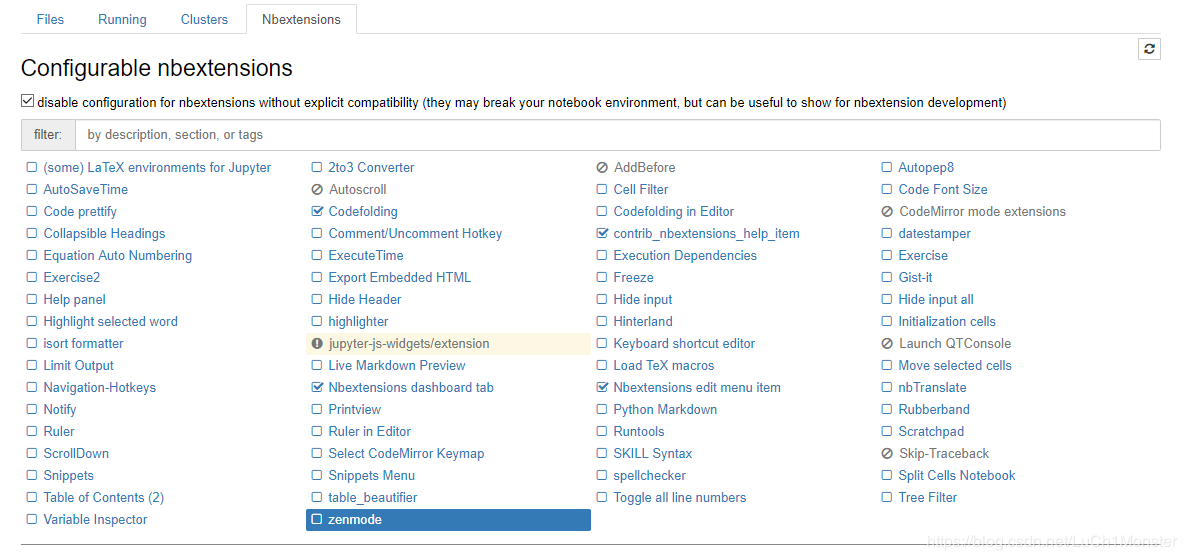
常用的插件
Code Prettify
Collapsible headings
Highlight selected word
Nofity
Ruler
Snippets Menu
table_beautifier
Codefolding
Execute Time
Hide Header
highlighter
Nbextensions dasnboard tab
Runtools
Toggle all line numbers
contrib_nbextensions_help_item
Freeze
Hide Input
Nbextensions edit menu item
Python Markdown
Scratchpad
Tree filter
datestamper
Hide input all
Scroll Down
Snippets
Table of Content
Variable Inspector
以下是两个摄像头进行拼接的代码,同理可以拼接N个。
效果如下:由于两个摄像头分辨率不一样,以及懒得resize成一样的大小,显示效果左边视频上下留黑了。

在下面再加两个视频窗口可以采用上下拼接:
————————————————
原文链接:https://blog.csdn.net/weixin_43002202/article/details/95459379
1. 首先输出配置文件
jupyter notebook –generate-config#输出配置文件
2.编辑配置文件
找到输出的配置文件后,找到#The directory to use for notebooks and kernels.这一行,将下面的c.NotebookApp.notebook_dir = ”改为c.NotebookApp.notebook_dir = ‘目标路径’
一、表单验证
前言
在Flask项目开发中针对提交表单的校验,可以使用Flask-WTF扩展库进行快速的字段校验,也可以进行页面快速渲染,并提供跨站请求伪造的保护功能。
1. 安装Flask-WTF
注意:
可以新建一个requirement.txt文档,里面写入将要导入的包
在Terminal中输入:pip install -r requirement.txt
2. 实现注册功能
2.1 注册表单模型定义
在定义的表单类中定义需要验证的username、password和password2字段,并实现如下校验:
校验密码password2和password相等
校验用户名是否存在
校验用户名的长度是否符合规范
users->forms.py
“`
# 导入扩展类
from flask_wtf import FlaskForm
# 导入验证字段
from wtforms import StringField, SubmitField, ValidationError
# 导入表单验证
from wtforms.validators import DataRequired, EqualTo
注意: 验证字段的方法名为: validate_字段(self, field)
2.2 定义注册视图函数
当HTTP请求为GET时,将表单验证对象返回给页面。
当HTTP请求为POST时,通过方法validate_on_submit()方法进行字段校验和提交判断,如果校验失败,则可以从form.errors中获取错误信息。
如果验证通过,则从form.字段.data中获取到字段的值。
users->views
2.3 模板展示
注册模板采用继承父模板base.html的形式。在register.html模压中分析如下:
注册register.html页面如下:
注意: 通过form.字段解析的input标签中可以自定义样式,如{{ form.字段(class=’xxx’, style=’color:red’) }}
3. 常见字段类型
4. 验证器
二、登录注册
前言
在flask中如何快速的实现登录注册注销功能,以及登录状态验证等功能? flask的扩展库中有Flask-Login库就可快速的实现以上的功能,实现起来是非常的便利。
1. 安装Flask-Login
2. 实现登录功能
2.1 定义login.html模板
2.2 实现登录功能
登录方法中定义被login_manager.user_loader装饰的回调函数,回调函数在如下两个地方被调用:
1)该函数表明当前用户登录成功时调用login_user()方法时,会被回调的函数。回调函数实现的功能是向会话上下文session中存储最为中间的键值对,key为user_id, value为当前登录用户的ID值。
2)回调函数在访问任何一个路由地址时也会被调用。
注意: 因为请求上下文在每次建立连接时,都需要获取当前登录用户并将当前登录用户设置为全局上下文current_user,因此回调函数返回的是当前登录系统的用户对象。
users->views.py
2.3 启动文件进行配置
session_protection: 设置存储用户登录状态的安全级别
login_view: 设置登录验证失败的跳转地址
2.4 访问首页,登录校验
使用装饰器login_required()进行登录校验。
核心思想: 校验session中是否存在key为user_id的键值对。如果校验成功,则继续访问被装饰的函数。如果校验失败,则跳转到启动文件中定义的login_manager.login_view定义的视图函数。
如果登录校验成功,则渲染index.html首页,在页面中可以解析全局变量current_user参数。
2.5 注销
使用logout_user()方法实现注销,核心功能就是删除当前会话上下文session中的user_id键值对。
# 退出
三、文件上传
1、配置路径
utils->settings.py
2、保存文件
3、html文件
四、完整的登录注册代码
manager.py
users->views.py
users->models.py
users->forms.py
utils->settings.py
templates->base.html
templates->base_main.html
templates->register.html
templates->login.html
templates->index.html
作者:晓晓的忍儿
链接:https://www.jianshu.com/p/9e343d10f7a2
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
lask_wtf是flask框架的表单验证模块,可以很方便生成表单,也可以当做json数据交互的验证工具,支持热插拔。
安装
Flask-WTF其实是对wtforms组件的封装,使其支持对flask框架的热插拔。
简单使用
flask_wtf定义字段
flask_wtf完全使用wtforms组件的字段模型,wtforms对字段的定义在fields模块;又分为core和simple,core模块定义了普通使用的字段,simple在core模块的基础上扩展了一些字段,这些字段会自动进行字段级别的校验。
字段类型
表单定义
字段的验证序列
字段的参数validators可以指定提交表单的验证序列,按照从左到右的顺序,默认的可选验证在wtforms.validators模块,已经封装的验证方法有:
自定义字段验证
如果默认的验证序列不满足我们的要求,我们可以通过继承的方式自定义字段。
触发StopValidation异常会停止验证链;
自定义表单验证
一般来说,如果对表单有额外需要的验证,一般自定义表单的额外的验证方法而不是重新自定义新的字段,而form已经为我们提供了这种方法。
看Form对象的源码:
Form对象调用validate函数时会自动寻找validate_%s的方法添加到验证序列,并在原先字段的验证序列验证完毕后执行。
表单对象
flask_wtf推荐使用Form对象的子类FlaskForm代替,该对象提供了所有表单需要的属性和方法。那么Form对象是如何自动实现表单功能的呢?
分析FlaskForm对象源码:
FlaskForm内部定义了一个Meta类,该类添加csrf保护的一些方法,所以创建表单的时候一定要导入FlaskForm而不是Form.
is_submitted:检查是否有一个活跃的request请求;
validate_on_submit:调用is_submitted和validate方法,返回一个布尔值,用来判断表单是否被提交;
validate:字段级别的验证,每个字段都有一个validate方法,FlaskForm调用validate会对所有的字段调用validate方法验证,如果所有的验证都通过返回Ture,否则抛出异常。
hidden_tag:获取表单隐藏的字段;
wrap_formdata:获取request中的form,每次form对象初始化时会执行该函数从request获取form。
重要属性
常用场景
登录验证
ajax请求转化表单
有时候我们没有html页面的表单,只有ajax请求的数据交互,但是想借用Form来定义接口和验证接收的数据,如果ajax的请求方法是(‘POST’, ‘PUT’, ‘PATCH’, ‘DELETE’)中的一种,FlaskForm会自动从request对象中调用request.form和request.get_json()方法来接收数据,因此这种方式十分方便。注意:get方法不再其中。
form启用csrf保护
默认csrf保护是开启的,只要在html文件中添加{{ form.csrf_token }},app必须设置SECRET_KEY参数。
一般数据csrf保护
同理必须设置SECRET_KEY参数。
参考
https://flask-wtf.readthedocs.io/en/stable/
http://www.pythondoc.com/flask-wtf/
https://www.cnblogs.com/sysnap/p/6568397.html # 表单验证器的总结
背景
加密学习
对称加密
对称密钥加密 , 又叫私钥加密。即信息发送的方和接受方用一个密钥去加密和揭秘数据。 最大的优势是 加解密速度快,适合对大量数据进行加密, 对称加密的缺点是密钥的管理和分配, 换句话说就是 如何把密钥发送到需要解密你的消息的人手里的问题。在发送密钥的过程中, 密钥有很大的风险被黑客拦截。 现实中的做法是将对称加密的密钥进行非对称加密然后传给需要他的人。
非对称加密
非对称加密系统, 又称公钥密钥加密。 非对称加密为数据的加密与解密提供了一种非常安全的方式。她使用了一对密钥, 私钥和公钥。 私钥只能有一方安全保管, 不能外泄, 而公钥可以发给任何请求她的人。非对称加密使用这对密钥中的一个进行加密, 而解密却需要一个另外一个密钥。 比如你去银行 你向银行请求公钥,银行将公钥发给你,你使用公钥对消息加密,那么只有私钥的持有人–银行才能对你的消息解密。 与对称加密的不同之处是, 银行不需要将私钥通过网络发送出去。因此安全性大大提高。 目前最常用的非对称加密算法是RSA算法。公钥机制灵活,但加密和解密速度却比对称密钥加密慢得多。 公钥机制灵活, 但是加密和解密速度却要比堆成加密慢很多。
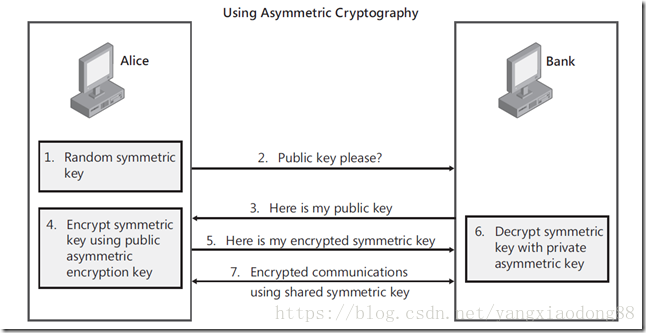
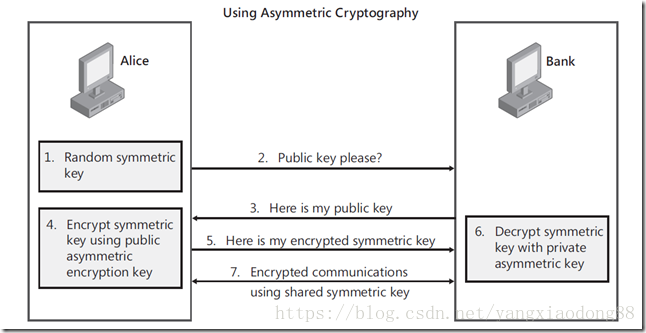
1) Alice需要在银行的网站做一笔交易,她的浏览器首先生成了一个随机数作为对称密钥。
(2) Alice的浏览器向银行的网站请求公钥。
(3) 银行将公钥发送给Alice。
(4) Alice的浏览器使用银行的公钥将自己的对称密钥加密。
(5) Alice的浏览器将加密后的对称密钥发送给银行。
(6) 银行使用私钥解密得到Alice浏览器的对称密钥。
(7) Alice与银行可以使用对称密钥来对沟通的内容进行加密与解密了。
(三)总结
(1) 对称加密加密与解密使用的是同样的密钥,所以速度快,但由于需要将密钥在网络传输,所以安全性不高。
(2) 非对称加密使用了一对密钥,公钥与私钥,所以安全性高,但加密与解密速度慢。
(3) 解决的办法是将对称加密的密钥使用非对称加密的公钥进行加密,然后发送出去,接收方使用私钥进行解密得到对称加密的密钥,然后双方可以使用对称加密来进行沟通。
base64 加密
python3 输入的都是 二进制 byte类型
注意:用于base64编码的,要么是ASCII包含的字符,要么是二进制数据
base64 是对称加密
base64 的加密和解密
———————–我是华丽的分界线,以下是代码————————–
import base64
s = ‘hello, world’
s = “你好”
# 加密
bs = base64.b64encode(s.encode(“utf8”))
print(bs)
# 解密
decode = base64.b64decode(bs)
print(decode)
print(decode.decode(“utf8”))
————————-我是华丽的分界线,以上是代码————————–
base64 是 一种用64 个字符来表示任意的二进制数据的方法。base64 可以成为密码学的基石。可以将任意二进制数据进行Base64 编码。 所有的数据都能被编码为并只有64个字符就能表示的文本文件。( 64字符:A~Z a~z 0~9 + / )编码后的数据~=编码前数据的4/3,会大1/3左右。
Base64编码的原理
1 将所有字符转化为ASCII码。
2 将ASCII码转化为8位二进制 。
3 将二进制3个归成一组(不足3个在后边补0)共24位,再拆分成4组,每组6位。
4 统一在6位二进制前补两个0凑足8位。
5 将补0后的二进制转为十进制。
6 从Base64编码表获取十进制对应的Base64编码。
Base64编码的说明
1 转换的时候,将三个byte的数据,先后放入一个24bit的缓冲区中,先来的byte占高位。
2 数据不足3byte的话,于缓冲区中剩下的bit用0补足。然后,每次取出6个bit,按照其值选择查表选择对应的字符作为编码后的输出。
3 不断进行,直到全部输入数据转换完成。
4 如果最后剩下两个输入数据,在编码结果后加1个“=”。
5 如果最后剩下一个输入数据,编码结果后加2个“=”。
6 如果没有剩下任何数据,就什么都不要加,这样才可以保证资料还原的正确性。
MD5
由于MD5模块在python3中被移除,在python3中使用hashlib模块进行md5操作
——————-我是华丽的分界线,以下是代码—————————–
import hashlib
str = “我真帅”
# 创建一个md5 对象
h1 = hashlib.md5()
# 此处必须声明encode
# 若写法为hl.update(str) 报错为: Unicode-objects must be encoded before hashing
h1.update(str.encode())
print(“加密前”, str)
print(“加密后”, h1.hexdigest())
——————–我是华丽的分界线,以上是代码——————————
sha1 加密
——————–我是华丽的分界线,以下是代码——————————
import hashlib
def str_encrypt(str):
“””
使用sha1加密算法,返回str加密后的字符串
“””
sha = hashlib.sha1(str)
encrypts = sha.hexdigest()
return encrypts
———————–我是华丽的分界线,以上是代码—————————-
简介
message-digest algorithm 5(信息-摘要算法)。经常说的“MD5加密”,就是它→信息-摘要算法。
md5,其实就是一种算法。可以将一个字符串,或文件,或压缩包,执行md5后,就可以生成一个固定长度为128bit的串。这个串,基本上是唯一的。
不可逆性
每个人都有不同的指纹,看到这个人,可以得出他的指纹等信息,并且唯一对应,但你只看一个指纹,是不可能看到或读到这个人的长相或身份等信息。
特点
1 压缩性:任意长度的数据,算出的MD5值长度都是固定的。
2 容易计算:从原数据计算出MD5值很容易。
3 抗修改性:对原数据进行任何改动,哪怕只修改1个字节,所得到的MD5值都有很大区别。
4 强抗碰撞:已知原数据和其MD5值,想找到一个具有相同MD5值的数据(即伪造数据)是非常困难的。
MD5长度
md5的长度,默认为128bit,也就是128个0和1的二进制串。这样表达是很不友好的。所以将二进制转成了16进制,每4个bit表示一个16进制,所以128/4 = 32 换成16进制表示后,为32位了。
为什么网上还有md5是16位的呢?
其实16位的长度,是从32位md5值来的。是将32位md5去掉前八位,去掉后八位得到的。
DES
Python加密库PyCryptodome
PyCrytodome 取代了 PyCrypto 。
安装与导入
Windows安装之前需要先安装Microsoft Visual c++ 2015。
下载地址:https://www.microsoft.com/en-us/download/details.aspx?id=48145
在Linux上安装,可以使用以下 pip 命令:
pip install pycryptodome
import Crypto
在Windows 系统上安装则稍有不同:
pip install pycryptodomex
import Cryptodome
DES算法为密码体制中的对称密码体制,又被称为美国数据加密标准。
DES是一个分组加密算法,典型的DES以64位为分组对数据加密,加密和解密用的是同一个算法。
DES算法的入口参数有三个:Key、Data、Mode。其中Key为7个字节共56位,是DES算法的工作密钥;Data为8个字节64位,是要被加密或被解密的数据;Mode为DES的工作方式,有两种:加密或解密。
密钥长64位,密钥事实上是56位参与DES运算(第8、16、24、32、40、48、56、64位是校验位,使得每个密钥都有奇数个1),分组后的明文组和56位的密钥按位替代或交换的方法形成密文组。
加密原理
DES 使用一个 56 位的密钥以及附加的 8 位奇偶校验位,产生最大 64 位的分组大小。这是一个迭代的分组密码,使用称为 Feistel 的技术,其中将加密的文本块分成两半。使用子密钥对其中一半应用循环功能,然后将输出与另一半进行“异或”运算;接着交换这两半,这一过程会继续下去,但最后一个循环不交换。DES 使用 16 个循环,使用异或,置换,代换,移位操作四种基本运算。
算法步骤
1)初始置换
其功能是把输入的64位数据块按位重新组合,并把输出分为L0、R0两部分,每部分各长3 2位,其置换规则为将输入的第58位换到第一位,第50位换到第2位……依此类推,最后一位是原来的第7位。L0、R0则是换位输出后的两部分,L0是输出的左32位,R0是右32位,例:设置换前的输入值为D1D2D3……D64,则经过初始置换后的结果为:L0=D58D50……D8;R0=D57D49……D7。
其置换规则见下表:
58,50,42,34,26,18,10,2,60,52,44,36,28,20,12,4,
62,54,46,38,30,22,14,6,64,56,48,40,32,24,16,8,
57,49,41,33,25,17,9,1,59,51,43,35,27,19,11,3,
61,53,45,37,29,21,13,5,63,55,47,39,31,23,15,7,
2)逆置换
经过16次迭代运算后,得到L16、R16,将此作为输入,进行逆置换,逆置换正好是初始置换的逆运算,由此即得到密文输出。
此算法是对称加密算法体系中的代表,在计算机网络系统中广泛使用.
加密和解密的过程
——————-我是华丽的分界线,以下是代码—————————–
from Cryptodome.Cipher import DES
key = b’abcdefgh’ # 密钥 8位或16位,必须为bytes
def pad(text):
“””
# 加密函数,如果text不是8的倍数【加密文本text必须为8的倍数!】,那就补足为8的倍数
:param text:
:return:
“””
while len(text) % 8 != 0:
text += ‘ ‘
return text
des = DES.new(key, DES.MODE_ECB) # 创建一个DES实例
text = ‘Python rocks!’
padded_text = pad(text)
encrypted_text = des.encrypt(padded_text.encode(‘utf-8’)) # 加密
print(encrypted_text)
# rstrip(‘ ‘)返回从字符串末尾删除所有字符串的字符串(默认空白字符)的副本
plain_text = des.decrypt(encrypted_text).decode().rstrip(‘ ‘) # 解密
print(plain_text)
———————我是华丽的分界线,以下是代码—————————
from Cryptodome.Cipher import DES
import binascii
# 这是密钥
key = b’abcdefgh’
# 需要去生成一个DES对象
des = DES.new(key, DES.MODE_ECB)
# 需要加密的数据
text = ‘python spider!’
text = text + (8 – (len(text) % 8)) * ‘=’
# 加密的过程
encrypto_text = des.encrypt(text.encode())
# 加密过后二进制转化为ASCII
encrypto_text = binascii.b2a_hex(encrypto_text)
print(encrypto_text)
# 解密需要ASCII 先转化为二进制 然后再进行解密
plaint = des.decrypt(binascii.a2b_hex(encrypto_text))
print(plaint)
———————我是华丽的分界线,以上是代码—————————
3DES
简介
3DES(或称为Triple DES)是三重数据加密算法(TDEA,Triple Data Encryption Algorithm)块密码的通称。它相当于是对每个数据块应用三次DES加密算法。
由于计算机运算能力的增强,原版DES密码的密钥长度变得容易被暴力破解。3DES即是设计用来提供一种相对简单的方法,即通过增加DES的密钥长度来避免类似的攻击,而不是设计一种全新的块密码算法。
3DES(即Triple DES)是DES向AES过渡的加密算法(1999年,NIST将3-DES指定为过渡的加密标准),加密算法,其具体实现如下:设Ek()和Dk()代表DES算法的加密和解密过程,K代表DES算法使用的密钥,M代表明文,C代表密文,这样:
3DES加密过程为:C=Ek3(Dk2(Ek1(M)))
3DES解密过程为:M=Dk1(EK2(Dk3(C)))
AES
简介
高级加密标准(英语:Advanced Encryption Standard,缩写:AES),在密码学中又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准。这个标准用来替代原先的DES,已经被多方分析且广为全世界所使用。经过五年的甄选流程,高级加密标准由美国国家标准与技术研究院(NIST)于2001年11月26日发布于FIPS PUB 197,并在2002年5月26日成为有效的标准。2006年,高级加密标准已然成为对称密钥加密中最流行的算法之一。
AES在软件及硬件上都能快速地加解密,相对来说较易于实作,且只需要很少的存储器。作为一个新的加密标准,目前正被部署应用到更广大的范围。
特点与思想
1,抵抗所有已知的攻击。
2,在多个平台上速度快,编码紧凑。
3,设计简单。
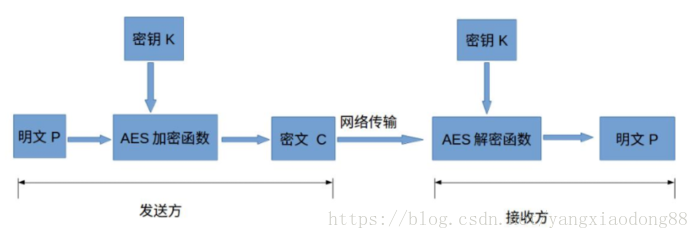
AES为分组密码,分组密码也就是把明文分成一组一组的,每组长度相等,每次加密一组数据,直到加密完整个明文。在AES标准规范中,分组长度只能是128位,也就是说,每个分组为16个字节(每个字节8位)。密钥的长度可以使用128位、192位或256位。密钥的长度不同,推荐加密轮数也不同。
一般常用的是128位
———————我是华丽的分界线,以下是代码—————————
from Cryptodome.Cipher import AES
from Cryptodome import Random
from binascii import a2b_hex
# 要加密的明文
data = ‘南来北往’
# 密钥key必须为 16(AES-128), 24(AES-192), 32(AES-256)
key = b’this is a 16 key’
# 生成长度等于AES 块大小的不可重复的密钥向量
iv = Random.new().read(AES.block_size)
print(iv)
# 使用 key 和iv 初始化AES 对象, 使用MODE_CFB模式
mycipher = AES.new(key, AES.MODE_CFB, iv)
print(mycipher)
# 加密的明文长度必须为16的倍数, 如果长度不为16的倍数, 则需要补足为16的倍数
# 将iv(密钥向量)加到加密的密钥开头, 一起传输
ciptext = iv + mycipher.encrypt(data.encode())
# 解密的话需要用key 和iv 生成的AES对象
print(ciptext)
mydecrypt = AES.new(key, AES.MODE_CFB, ciptext[:16])
# 使用新生成的AES 对象, 将加密的密钥解密
decrytext = mydecrypt.decrypt(ciptext[16:])
print(decrytext.decode())
———————我是华丽的分界线,以上是代码—————————
RSA
非对称加密
典型的非对称加密
典型的如RSA等,常见方法,使用openssl ,keytools等工具生成一对公私钥对,使用被公钥加密的数据可以使用私钥来解密,反之亦然(被私钥加密的数据也可以被公钥解密) 。
在实际使用中私钥一般保存在发布者手中,是私有的不对外公开的,只将公钥对外公布,就能实现只有私钥的持有者才能将数据解密的方法。 这种加密方式安全系数很高,因为它不用将解密的密钥进行传递,从而没有密钥在传递过程中被截获的风险,而破解密文几乎又是不可能的。
但是算法的效率低,所以常用于很重要数据的加密,常和对称配合使用,使用非对称加密的密钥去加密对称加密的密钥。
简介
RSA加密算法是一种非对称加密算法。在公开密钥加密和电子商业中RSA被广泛使用。
该算法基于一个十分简单的数论事实:将两个大素数相乘十分容易,但那时想要对其乘积进行因式分解却极其困难,因此可以将乘积公开作为加密密钥,即公钥,而两个大素数组合成私钥。公钥是可发布的供任何人使用,私钥则为自己所有,供解密之用
而且,因为RSA加密算法的特性,RSA的公钥私钥都是10进制的,但公钥的值常常保存为16进制的格式,所以需要将其用int()方法转换为10进制格式。
————————我是华丽的分界线,以下是代码—————————
import rsa
# rsa加密
def rsaEncrypt(str):
# 生成公钥、私钥
(pubkey, privkey) = rsa.newkeys(512)
print(“pub: “, pubkey)
print(“priv: “, privkey)
# 明文编码格式
content = str.encode(‘utf-8’)
# 公钥加密
crypto = rsa.encrypt(content, pubkey)
return (crypto, privkey)
# rsa解密
def rsaDecrypt(str, pk):
# 私钥解密
content = rsa.decrypt(str, pk)
con = content.decode(‘utf-8’)
return con
(a, b) = rsaEncrypt(“hello”)
print(‘加密后密文:’)
print(a)
content = rsaDecrypt(a, b)
print(‘解密后明文:’)
print(content)
———————我是华丽的分界线,以下是代码—————————
import rsa
import binascii
def rsa_encrypt(rsa_n, rsa_e, message):
key = rsa.PublicKey(rsa_n, rsa_e)
message = rsa.encrypt(message.encode(), key)
message = binascii.b2a_hex(message)
return message.decode()
pubkey_n = ‘8d7e6949d411ce14d7d233d7160f5b2cc753930caba4d5ad24f923a505253b9c39b09a059732250e56c594d735077cfcb0c3508e9f544f101bdf7e97fe1b0d97f273468264b8b24caaa2a90cd9708a417c51cf8ba35444d37c514a0490441a773ccb121034f29748763c6c4f76eb0303559c57071fd89234d140c8bb965f9725’
pubkey_e = ‘10001’
rsa_n = int(pubkey_n, 16)
rsa_e = int(pubkey_e, 16)
message = ‘南北今天很忙’
print(“公钥n值长度:”, len(pubkey_n))
aa = rsa_encrypt(rsa_n, rsa_e, message)
print(aa)
———————我是华丽的分界线,以下是代码—————————
”’
RSA算法
”’
from Cryptodome.PublicKey import RSA
from Cryptodome.Cipher import PKCS1_OAEP, PKCS1_v1_5
class MyRSA():
def create_rsa_key(self, password):
“””
创建RSA密钥
步骤说明:
1、从 Crypto.PublicKey 包中导入 RSA,创建一个密码
2、生成 1024/2048 位的 RSA 密钥
3、调用 RSA 密钥实例的 exportKey 方法,传入密码、使用的 PKCS 标准以及加密方案这三个参数。
4、将私钥写入磁盘的文件。
5、使用方法链调用 publickey 和 exportKey 方法生成公钥,写入磁盘上的文件。
“””
key = RSA.generate(1024)
encrypted_key = key.exportKey(passphrase=password.encode(“utf-8″), pkcs=8,
protection=”scryptAndAES128-CBC”)
with open(“my_private_rsa_key.bin”, “wb”) as f:
f.write(encrypted_key)
with open(“my_rsa_public.pem”, “wb”) as f:
f.write(key.publickey().exportKey())
def encrypt(self, plaintext):
# 加载公钥
recipient_key = RSA.import_key(
open(“my_rsa_public.pem”).read()
)
cipher_rsa = PKCS1_v1_5.new(recipient_key)
en_data = cipher_rsa.encrypt(plaintext.encode(“utf-8”))
return en_data
# print(len(en_data), en_data)
def decrypt(self, en_data, password):
# 读取密钥
private_key = RSA.import_key(
open(“my_private_rsa_key.bin”).read(),
passphrase=password
)
cipher_rsa = PKCS1_v1_5.new(private_key)
data = cipher_rsa.decrypt(en_data, None)
return data
# print(data)
mrsa = MyRSA()
mrsa.create_rsa_key(‘123456’)
e = mrsa.encrypt(‘hello’)
d = mrsa.decrypt(e, ‘123456’)
print(e)
print(d)
———————我是华丽的分界线,以上是代码—————————
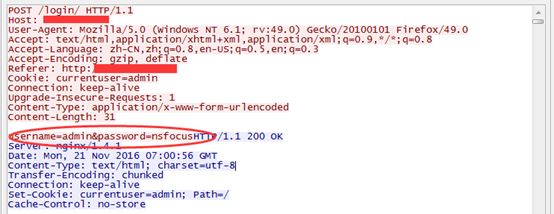
HTTP采用明文传输,如果不对用户密码进行加密处理的话,会导致用户密码明文暴露在网络,通过监听抓包很容易获得。此问题处理方法一般有使用https代替http或对http 表单提交数据进行加解密处理。这里分享的是用RSA非对称加密算法对数据进行加解密,前端js使用公钥进行加密,后端python使用私钥进行解密。
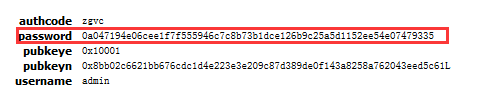
HTTP采用明文传输,如果不对用户密码进行加密处理的话,会导致用户密码明文暴露在网络,通过监听抓包很容易获得,如下图:
此问题处理方法一般有使用https代替http或对http 表单提交数据进行加解密处理,这里分享的是用RSA非对称加密算法对数据进行加解密,前端js使用公钥进行加密,后端python使用私钥进行解密。
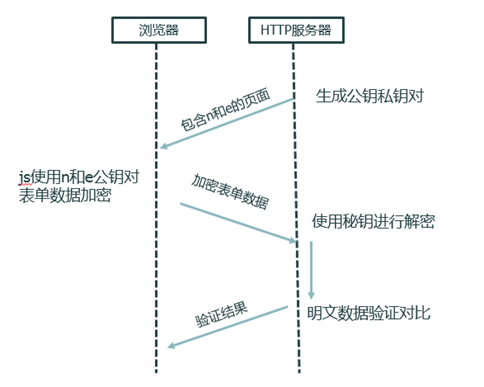
RSA加密算法简而言之就是服务端生成公钥私钥对,公钥给客户端,客户端拿着公钥去加密数据,然后服务端用私钥去解密数据。
RSA算法中,n、e两个参数决定公钥,n和d决定私钥。在本例的B/S应用中,来往数据如下图:
具体实现
生成公钥私钥对
为了避免加密后的密码重复使用,后端处理时每次请求都重新生成公钥私钥对。
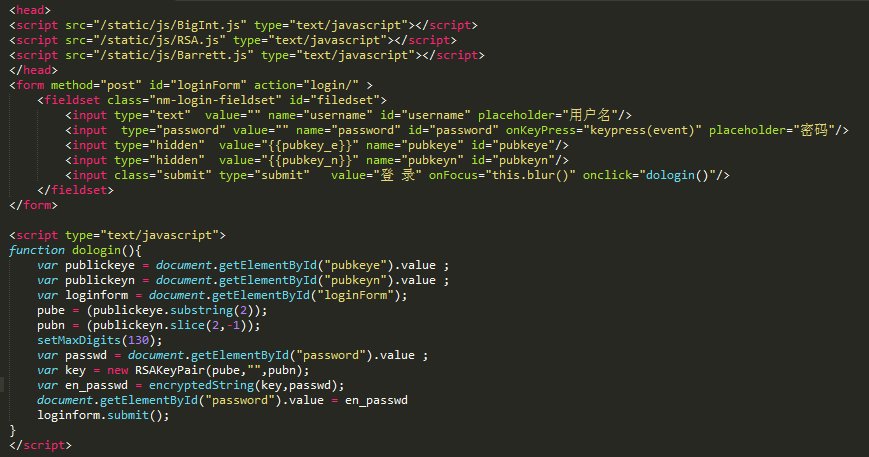
当用户请求登录时,生成公钥私钥对,并将n和e写在http页面中返回给前端。需要注意的是生成e和n需要转成十六进制再传递给前端,代码如下:
前端js获取公钥n和e,并使用公钥对用户输入的密码进行加密,然后将加密后的密码发送给服务器请求认证。需要注意的是前端需要将python传输过来的16进制数据进行处理,去掉前面的0x和后面的L。
后端使用私钥进行解密验证
验证一下,通过firebug看到post数据中密码已经进行了加密,如下图: