网站自适应,很多人都认为是很高级需要很多时间去实现的东西,不愿意去把一个现成的网站改成自适应,宁愿单独另外做一个移动站。我之前觉得实现网站自适应,要设计很多套CSS,并且要结合jQuery,来实现自适应不同的设备。我还以为要重新设计文章的图片,或者要用到JavaScript来控制图片尺寸,因为图片过大就会超出手机屏幕,而这个工作量是非常可怕的。种种顾虑使我一直不敢着手开刀,造成至今网站还只是一个PC版,而也没有多做一个移动版。
经常在群里看到大家都说移动流量怎么多怎么多,有的还说移动流量大大超过了PC流量,说移动流量的广告点击率也比PC流量高,潜移默化的作用,我也慢慢受到了感染,于是决定把网站改成自适应!
我为什么是把网站改为自适应,而不是改为一个单独的移动站?因为我想一劳百逸,不想同时维护PC站和移动站,这将为日后更新文章节省大量的时间。
由于是第一次接触,没有实际经验,所以需要边找资料看案例边修改代码。
令我感到非常意外的是,我竟然仅需一天时间就完成了修改工作!
先看看我的修改成果吧
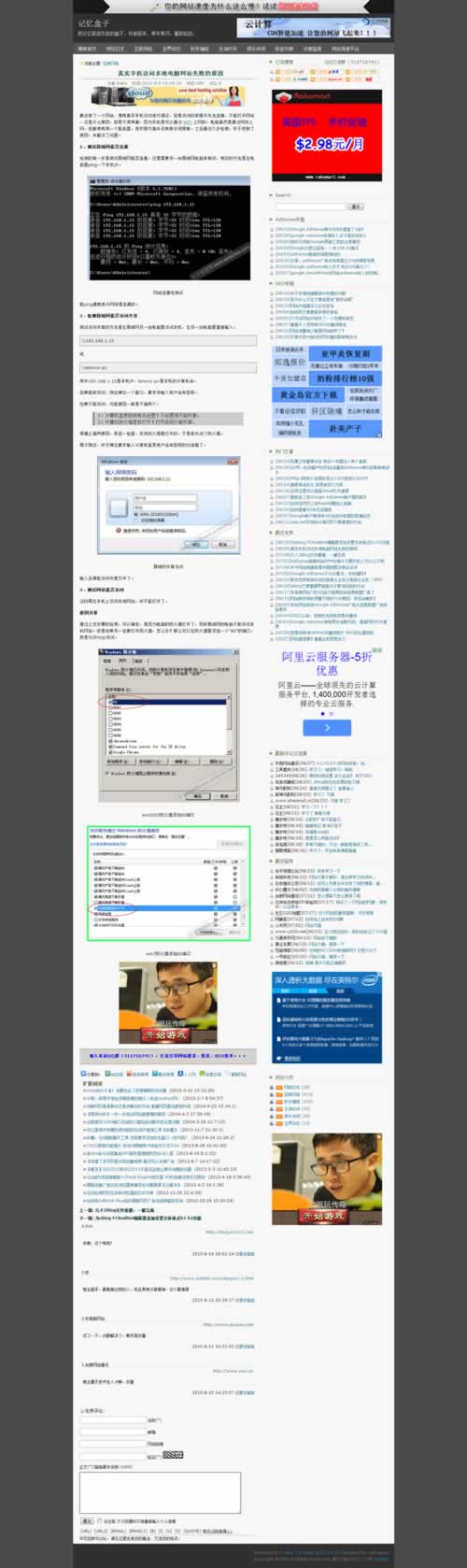
PC版网页
PC版网页
手机版网页
手机版网页
此手机版效果图显示的内容比较少,事实上,手机版网页中,在文章结尾也显示Google广告,文章结尾还有用户留言,用户照样可以在手机上评论,此外,“扩展阅读”后面还显示了PC版中的侧栏几个栏目的文章列表,最后,在页尾的搜索框着色层上方投放了百度移动的自适应广告。
网站改为自适应有多简单?
下面就说说如何把网页改为自适应吧,我为什么说很简单?因为你不需要任何高深的网页设计技术,你只需要懂一点html、一点css,而修改耗时对于一张普通网页来说,确实只需几个小时。
我把整个改动过程分为两个步骤。
第一步,非常简单,把如下代码直接复制到<head></head>里面。
<meta http-equiv=”Cache-Control” content=”no-transform” />
<meta http-equiv=”Cache-Control” content=”no-siteapp” />
<meta name=”viewport” content=”width=device-width,initial-scale=1.0,user-scalable=yes” />
前面两个meta,no-siteapp和no-transform,是告诉搜索引擎不要把网页转码。第三个meta,声明网页可以缩小放大。
第二步,在<head></head>里加上如下css代码。
<style type=”text/css”>
@media(max-width:960px)
{
}
</style>
这段css代码,意思是在屏幕宽度小于960px的时候执行的样式,当然你可以把960px改为其他更小的宽度,例如760px。
接下来,我们要做的就是把那些不需要在手机网页上显示的内容隐藏掉。如何隐藏?这就需要看懂网页的html代码了,需要分析每一个模块使用的div,例如头部的div、导航栏的div、正文的div、侧栏的div、页脚的div,然后,我们就使用css隐藏不用显示的div,代码很简单,就是display:none。
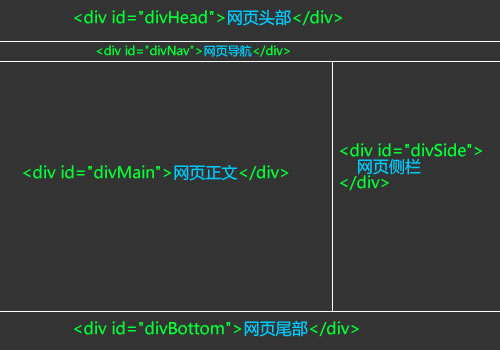
举例说明,比如网页结构如下图所示:
网页结构图
手机网页只需显示正文,我们把其他部分全部隐藏,代码如下:
<style type=”text/css”>
@media(max-width:960px)
{
/* 网页全屏显示 */
body {width:100%;}
/* 正文全屏显示 */
#divMain{width:100%}
/* 为了避免正文图片超出屏幕宽度 */
/* 正文图片宽度最多是屏幕宽度的90% */
#divMain img{max-width:90%}
/* 隐藏头部、导航、侧栏、页脚 */
#divHead{display:none}
#divNav{display:none}
#divSide{display:none}
#divBottom{display:none}
}
</style>
这样,当在手机浏览网页时,就只显示正文了。
网页自适应就是这样做的!
看了这个实例,是不是很简单?网页自适应就是这样做的!
不过要把手机网页自适应得有头有尾,你还需要补充编写一些代码,例如编写针对手机网页的头部、导航和页脚的div,编写后默认为隐藏,在手机里再显示。
如下图所示网页结构:
包含手机模块的网页结构
css就可以这样写
<style type=”text/css”>
/* 默认隐藏手机版头部、导航和页脚 */
#divHead_mobile{display:none}
#divNav_mobile{display:none}
#divBottom_mobile{display:none}
@media(max-width:960px)
{
/* 网页全屏显示 */
body {width:100%;}
/* 正文全屏显示 */
#divMain{width:100%}
/* 为了避免正文图片超出屏幕宽度 */
/* 正文图片宽度最多是屏幕宽度的90% */
#divMain img{max-width:90%}
/* 隐藏头部、导航、侧栏、页脚 */
#divHead{display:none}
#divNav{display:none}
#divSide{display:none}
#divBottom{display:none}
/* 显示手机版头部、导航和页脚 */
#divHead_mobile{display:block}
#divNav_mobile{display:block}
#divBottom_mobile{display:block}
}
</style>
至此,你就可以自适应设计出一个漂亮的手机版页面了。