Introduction
This article answers the question often asked about Outlook Add-In plug-in: Once an Outlook Add-In solution is deployed on the client computer, how can any future revisions to the solution automatically be made available to the client computer seamlessly? This article attempts to provide end-to-end steps on how the Update Process for Outlook Add-Ins Solutions needs to be handled once the application is deployed on the end-user machine.
Scenario
Normally an application is deployed on the client computer in two ways: One is using the “setup” (using either Microsoft’s or third party setup projects) or using the “publish” or more popularly known as “Click-once”.
As you can see, there are definite reasons why you need to choose one over the other. Click-once is appealing as this method can be used to publish the application and the updates can be made automatically at the end user. But using this method, an application that requires registry entries cannot be deployed. The traditional method can be used to make registry entries but the automatic updates are difficult unless the auto-updater component is custom developed.
The method explained here uses a combination of both the methods to achieve registry updates during the installation and also to push the updates seamlessly to the end user.
Prerequisites
Before we begin, Visual Studio 2005 Tools for Office (VSTO) needs to be installed to create custom add-ins for Outlook in Visual Studio 2005. This article does not address the pre-requisites to develop the Outlook Add-In.
Using the code
Step 1: Create a simple Outlook Add-In project using VS2005.
In Microsoft Visual Studio .NET 2005, open the New Project dialog box, open Visual C#, select Office and click Outlook Add-in.
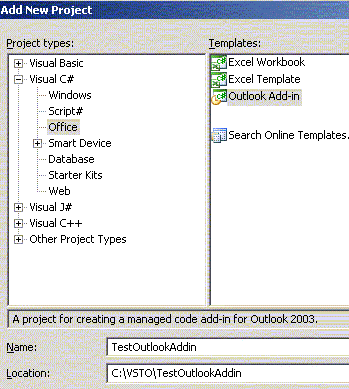
Rename the project as TestOutlookAddin and click OK. As you would expect, Visual Studio creates a project called TestOutlookAddin and it also
automatically creates a setup project (TestOutlookAddinSetup). This setup project helps in installing the add-in on the client’s computer.
Under Outlook folder in Solution Explorer, open ThisApplication.cs and add logic to create a Top Menu Item under ThisApplication_Startup event procedure. Refer to the attached sample application for details.
// Get the Outlook menu bar.
_menuBar = this.ActiveExplorer().CommandBars.ActiveMenuBar;
// Get the index of the Help menu on the Outlook menu bar.
_helpMenuIndex = _menuBar.Controls[_MENU_BEFORE].Index;
// Add the top-level menu right before the Help menu.
_topMenu =
(Office.CommandBarPopup)_menuBar.Controls.Add(
Office.MsoControlType.msoontrolPopup,
Type.Missing,
Type.Missing,
_helpMenuIndex,
true);
// Set the Caption from App.Config
_topMenu.Caption =
System.Configuration.ConfigurationManager.AppSettings
["TopMenuCaption"];
// Make the new Menu Item visible
_topMenu.Visible = true;
key="MenuBeforeLocation" value="Help" />
key="TopMenuCaption" value="Demo" />
Step 2: Publish the Outlook Add-in project Solution files – TestOutlookAddin
Use the Publish Wizard under Properties to deploy the solution files to a location on a Server that would enable automatic updates to the application on the client computer. This follows the manifest approach that gives more flexibility in maintaining and updating the application without touching the registry again.
In Solution Explorer, right-click the TestOutlookAddin project node and click on Properties on the shortcut menu.
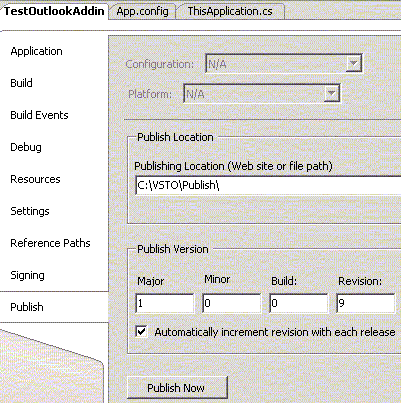
Select Publish on the left pane. Make sure the Checkbox ‘Automatically increments revision with each release’ is checked.
Use either of the two methods to Publish the solution. This would copy the revised assemblies, application manifest and configuration manifest to the published location.
Method 1
After selecting Publish on the left Pane as illustrated above, choose Publishing Location (Web site or file path) that would allow automatic updates to the application on the client computer.
You may choose either File System, Local IIS or Remote Site . If you choose Remote Site option, the FrontPage Server Extensions need to be enabled on the Server.
Click on the Publish Now button.
Method 2 – Using the Publish Wizard
In Solution Explorer, right-click the TestOutlookAddin project node and click on Publish on the shortcut menu.
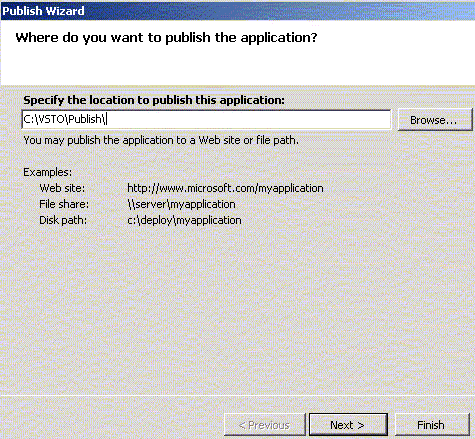
Specify the centralized location to publish this application. Click on the Browse button to choose either File System, Local IIS or Remote Site . If you choose Remote Site option, the FrontPage Server Extensions need to be enabled on the Server.
Click on Next button. Click on Finish to publish your application.
You may have noticed that when the Add-in project TestOutlookAddin was created in VS2005, the automatically created setup project TestOutlookAddinSetup contains the Primary output from TestOutlookAddin. Thus the necessary published information like location and version number are available when you rebuild TestOutlookAddinSetup and subsequently in the Windows Installer (.msi) file that will be distributed to your Clients.
Step 3: Add Prerequisites to the Setup Project – TestOutlookAddinSetup
Once your Outlook Add-In application is published onto a centralized location, it is time to build the Setup project and distribute it to your Clients as a Windows Installer (.MSI) file. You will now modify the Setup project to check for basic prerequisites.
In Solution Explorer, right-click the TestOutlookAddinSetup project node and click on Properties on the shortcut menu.
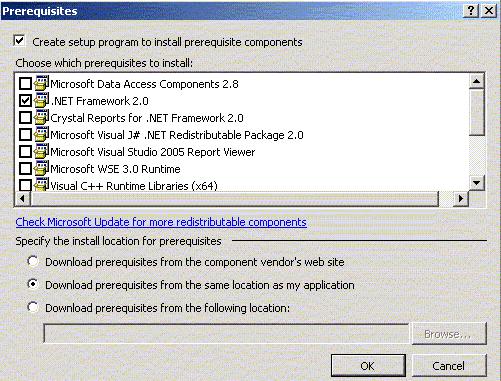
Click on the prerequisites button and make sure the Create setup program to install prerequisite components is checked.
Check the .NET Framework 2.0 prerequisite from the list.
Specify the install location for prerequisites accordingly. In the sample application, the ‘Download prerequisites from the same location as my application’ is checked.
Click OK twice to exit the Properties Page.
Step 4: Add Launch Conditions to the Windows Installer (.msi) file
In this article, we check only two basic prerequisites namely, Visual Studio 2005 Tools for Office Runtime and the Office primary interop assemblies.
In Solution Explorer, right-click the TestOutlookAddinSetup project node, point to View on the shortcut menu and click Launch Conditions.
To add a launch condition for the Visual Studio 2005 Tools for Office Runtime
In the Launch Conditions editor, right-click Requirements on Target Machine, and then click Add Windows Installer Launch Condition.
Select the newly added search condition, Search for Component1 and rename to VSTO Runtime.
Right click on the above search condition and select the Properties Window. In the Properties window, type {D2AC2FF1-6F93-40D1-8C0F-0E135956A2DA} into the ComponentId property and change the value of Property to CHECK_VSTO_RUNTIME.
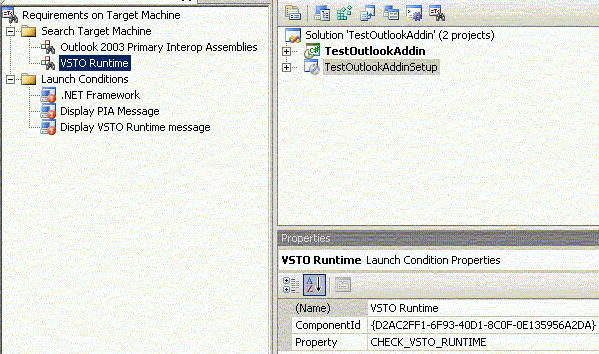
Select the newly added launch condition, (Condition1) and rename it to Display VSTO Runtime Message.
In the Properties window, change the value of the Condition property to CHECK_VSTO_RUNTIME and leave the InstallURL property blank.
Change the value of the Message property to ‘The Visual Studio 2005 Tools for Office Runtime is not installed on this Computer’.
To add a launch condition for the Outlook 2003 Primary Interop Assembly
In the Launch Conditions editor, right-click Requirements on Target Machine, and then click Add Windows Installer Launch Condition.
Select the newly added search condition, Search for Component1 and rename the search condition to Outlook 2003 Primary Interop Assemblies.
Right click on the above search condition and select Properties Window. In the Properties window, type {14D3E42A-A318-4D77-9895-A7EE585EFC3B} into the ComponentId property and change the value of Property to CHECK_OUTLOOK2003_PIA.
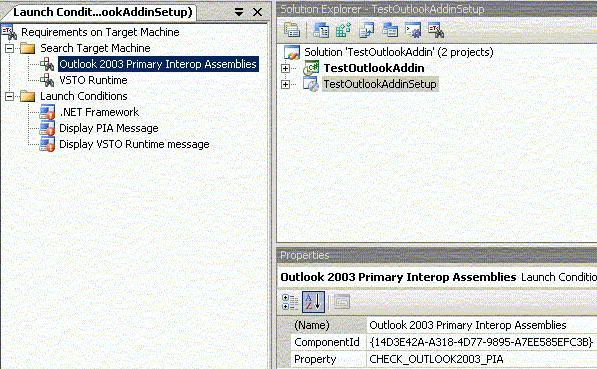
Select the newly added launch condition, (Condition1) and rename it to Display PIA message.
In the Properties window, change the value of the Condition property to CHECK_OUTLOOK2003_PIA and leave the InstallURL property blank.
Change the value of the Message property to ‘The Office 2003 Primary Interop Assemblies have not been installed on this Computer’.
Step 5: Installing the Add-in Solution
In Solution Explorer, right-click the TestOutlookAddinSetup project node and click on Rebuild on the shortcut menu to rebuild your solution. This would create the Windows Installer file TestOutlookAddinSetup.msi.
To install the solution on your development machine using VS2005, in Solution Explorer, right-click the TestOutlookAddinSetup project node and click Install on the shortcut menu.
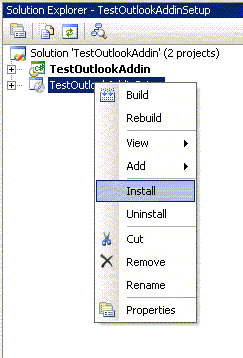
To install the solution on the Client computer, distribute the Windows Installer file TestOutlookAddinSetup.msi to your client and install the same.
The installation creates the necessary registry entry for the application Add-In on the Client Computer when all prerequisites are met.
Note: It is important to note that the Add-In project TestOutlookAddin was published to some location prior to the installation of the Add-In solution on the client computer.
Step 6: Look for the impact of the Add-in in Outlook
The attached sample application adds a new menu item to Outlook just before the HELP menu. If the installation was successful, the next time Outlook is opened, you should see the new Menu item Demo on the top.

Step 7: Test the automatic Update Process
Now that your application has been deployed on your client computer, changes that you make to your solution on the development server should be automatically made available on the Client computer. VSTO uses a concept similar to the ClickOnce to achieve this. In the attached sample application we shall change the caption of the Menu item in the app.config.
In the attached sample application TestOutlookAddin, change the Value of the field TopMenuCaption in App.config to DemoRevision.
In Solution Explorer, right-click the TestOutlookAddin project node and click on Publish on the shortcut menu.
Important: Do not change the location of the Publish at this stage. The local application manifest file on the Client computer contains the published Location and version information that would enable the automatic updating process. If the location needs to be changed for some reason, you will have to distribute the Windows Installer file to your clients for re-installation.
Step 8: Looking for the desired changes in Outlook
Close and re-open the Outlook application on the client computer to see the impact of the new changes to the Add-In application. The new Menu item on the top would have the revised text DemoRevision instead of Demo.
Note: You did not rebuild or re-install your setup application TestOutlookAddinSetup this time.
The following events take place when Outlook is re-opened:
The VSTO Runtime uses the information in the application manifest on the client computer to locate the deployment manifest.
The version of the deployment manifest is checked against the version of the application manifest on the client computer. If the version of the deployment manifest on the server is newer than the application manifest on the client computer, the new assemblies and the new application manifest are downloaded automatically.
The local copy of the application manifest is overwritten with the latest version.
When the user starts Outlook the next time, the new assemblies are executed on the client computer and the changes are reflected in the Outlook application.
Summary
This article demonstrates that once the Outlook Add-In project is deployed on the client computer using the Microsoft Installer (.msi) file created in the setup project of VS2005, further updates to the application can be automatically made available on the Client Computer by using the Publish option of the Add-In project in VS2005. As long as the path to the local application manifest is the same, no further changes in the registry entries are needed for this Add-in. The Publish option will accommodate all updates from here.